
IT Service Management: fare ordine nell’assistenza IT
Alfiero Santarelli
Anche in tempi di cloud, dove tutto sembra invisibile, digitale e pulito, l’immagine dell’IT è spesso legata a grovigli di cavi, PC smontati e post-it sul muro, e lo stesso lavoro di assistenza, supporto e manutenzione dell’infrastruttura dà spesso un’immagine di disordine. Eppure esiste una ricetta che può guidare i team IT a presentarsi come fornitori strutturati di servizi: questa ricetta va sotto il nome di “IT Service Management” ed è applicata da un numero crescente di aziende grandi e piccole.
Conoscete Marie Kondo? E’ una scrittrice giapponese che ha raggiunto fama mondiale spiegando alle persone come mettere in ordine la propria casa. La sua filosofia, ridotta ai minimi termini, consiglia di rivedere ogni cosa che possediamo, capire quale “ci dà gioia” e buttare il resto. L’obiettivo finale è quello di sentirsi meglio, riordinando la propria casa e per estensione anche una parte delle nostre vite.
Noi siamo gente di IT, e ci basterebbe fare un po’ di “Marie Kondo” nella gestione delle nostre attività. Quindi, ecco un breve “Konmari” dell’assistenza IT, che si può applicare a vari contesti a seconda del loro… livello di caos.
Dimenticavo: quando si lavora in casa è sempre utile avere qualche strumento a portata di mano. Io ho una spiccata preferenza per il JIRA Service Desk di Atlassian, ma voi naturalmente potete utilizzare ciò che preferite!
Passo 1: Raccogliere tutto in un unico punto
La prima cosa da fare è raccogliere tutte le richieste in un unico punto. Questo perché altrimenti è impossibile decidere cosa è urgente, cosa è importante, e non avremo uniformità nelle informazioni raccolte.
Gli utenti devono essere consapevoli dell’esistenza di un unico punto di contatto: non importa come segnalano il problema, arriverà sempre nello stesso “cesto” a cui accede tutta l’assistenza. Questo implica il fatto, non secondario, che “chiamare non risolve il problema più velocemente dell’invio di un’e-mail”.
Quindi, care amiche e cari amici, prendete
- Le chiamate telefoniche
- I messaggi di testo
- Il tizio che mette dentro la testa all’ora di pranzo e dice: “Pensi di poterlo fare?”.
- Qualsiasi tipo di chat (chat aziendale, Whatsapp, Telegram, …)
e trasformateli in un insieme di ticket. Il ticket è una scheda o un form che raccoglie informazioni come queste:
- Problema: nel mio ufficio non riesco a stampare
- Chi: Maria Schiaparelli (m.schiaparelli@xxx.it)
- Reparto: progettazione tecnica, piano 1
- Categoria: stampante
- Data richiesta: 7 maggio 2020
- Urgenza: Alto
In JIRA Service Desk il ticket è il cuore di tutto il sistema, e prende la forma di una issue nella quale vengono registrate tutte le informazioni utili, all’interno di elementi chiamati “campi”.
Questo tipo di struttura informativa è orientata a prioritizzazione (cosa devo gestire prima e perché) e azione (come devo reagire, e in base a quali elementi).
Ad esempio, la prioritizzazione è influenzata dalla data della richiesta (è più probabile che si serva una richiesta di marzo di quella indicata sopra) e dall’urgenza. Notate che l’urgenza è una categoria astratta, e non dipende dalla persona.
L’azione è determinata dalle informazioni logistiche: sapete di dover lavorare su una stampante, sapete dove trovarla, e più o meno sapete cosa non funziona. Potete individuare la persona che si occupa delle stampanti e mandarla in quell’ufficio.
All’inizio è inutile sperare che il cliente, interno o esterno, si occupi di questo: il lavoro sporco tocca a voi. Ecco qualche esempio delle cose che vi toccherà fare, possibilmente per un tempo limitato:
- trascrivere ogni cosa che viene detta a voce
- copiare il messaggio da Whatsapp
- trasformare l’immagine in un allegato
- … eccetera
L’arte nel progettare un “buon ticket” è quella di trovare il giusto equilibrio tra le informazioni necessarie per affrontare il problema, quelle necessarie a gestire la segnalazione, e ciò che il team IT ha effettivamente il tempo e la possibilità di compilare.
Quando si sarà consolidata l’abitudine a convogliare ogni richiesta verso un ticket, potrete chiedere ai vostri utenti di creare il ticket e aggiungere le informazioni iniziali, con la promessa implicita di velocizzare la risposta. Ci sarà naturalmente una differenza di tono e di stile tra il modo in cui gli utenti vedono un ticket e il modo in cui lo vede il team IT. Ad esempio:
- Invece che mettere di fronte all’utente la parola “Problema”, potete scrivere “perché ci stai contattando?” “cosa c’è che non va?”
- Al posto di parole asettiche come “Categoria”; si può mettere una lista di dispositivi e chiedere “quale di questi non funziona?”
Questo è uno dei tratti caratteristici di JIRA Service Desk, che associa alle proprie issue interne (ricche di dettagli tecnici, spesso incomprensibili per l’utente) una versione user friendly che permette di rinominare ogni singolo campo, di associare una breve spiegazione della sua funzione e di selezionare cosa l’utente deve vedere e cosa no.
Passo 2: affidare la richiesta alla persona giusta
Ciò che si vuole evitare sono i classici “antipattern” dell’assistenza:
- l’amicone del calcetto che ti risolve le cose prima degli altri
- il guru che sa tutto, davanti al quale si forma una coda come dal macellaio
Con un sistema di ticketing non è l’utente a decidere chi fa il lavoro: è un IT manager, il team o il sistema stesso. Questo processo si chiama talvolta triage, come quello che si svolge al pronto soccorso di un ospedale.
Un altro criterio di progettazione rilevante è la logica che si applica alla distribuzione dei ticket, ad esempio:
– si assegna una persona responsabile o un sottogruppo responsabile per i ticket di una determinata categoria
– una certa persona viene incaricata dei ticket provenienti da un determinato reparto o cliente
– round-robin: i biglietti saranno assegnati in sequenza, un membro del team dopo l’altro, possibilmente bilanciando il carico di lavoro
I raggruppamenti di ticket sono chiamati code, analogamente alle code in banca, tipicamente gestite in base al principio “primo arrivato, primo servito”. In realtà, una coda di ticketing è più simile a un elenco o a una tabella che può essere ordinata secondo criteri diversi:
- l’”età” del ticket: quanto tempo è passato dal momento della sua apertura
- l’urgenza
- il tipo di ticket
Anche questi aspetti sono gestiti in modo semplice da JIRA Service Desk: in particolare, le code altro non sono che dei filtri che individuano e ordinano i ticket in base a campi e priorità. Il gestore del Service Desk può creare tutte le code che desidera.
Passo 3: introdurre la logica di servizio
Nella denominazione “IT Service Management” è implicito il concetto di “servizio”, e però nella maggior parte dei casi ciò con cui abbiamo a che fare è ben lontano dall’idea di servizio: si tratta semplicemente di singole azioni svolte in modo reattivo da persone che, spesso, preferirebbero fare altro.
Cosa contraddistingue un servizio? Ecco alcuni elementi senza pretesa di completezza:
- essere rivolto all’utente o al cliente
- garantire tempi certi di servizio
- avere una qualità misurabile
- prevedere una logica di continuo miglioramento
I passi precedenti sono serviti a metterci nelle condizioni di introdurre questa logica. Vediamo come.
Prima di tutto, la standardizzazione delle attività e la loro centralizzazione rendono molto più semplice definire delle metriche: cose come “il tempo medio per risolvere una questione”, “il numero di richieste risolte in un mese”. Prima, ovviamente, era difficile mescolare i messaggi volanti, le risposte a voce e le mail ricevute dai vari uffici, e soprattutto tracciare l’attività svolta.
Più delicato è il tema del continuo miglioramento: il miglioramento va definito in termini quantitativi, e quindi deve essere basato a sua volta su opportune metriche. Questo però ci fa scivolare spesso in un altro antipattern, la “schiavitù delle metriche” in base al quale gli indicatori vengono utilizzati come strumenti di pressione, e di conseguenza il team di servizio reagisce lavorando in funzione delle metriche stesse, anziché della qualità del servizio.
Un esempio pratico: l’IT manager definisce il numero di interazioni con l’utente come un indicatore da tenere basso; il team, di conseguenza, prende l’abitudine di chiudere il ticket alla prima risposta. Questo migliora enormemente le metriche ma può dare all’utente una sensazione di scarsa attenzione.
I tempi di servizio, usualmente, vengono tenuti sotto controllo dai Service Level Agreement, “accordi sul livello di servizio”. Questo è un termine che potete avere incontrato in altri contesti, come i contratti di hosting, dove il livello di servizio è solitamente definito come percentuale di uptime. Nei servizi di assistenza IT è usuale stabilire livelli di servizio in termini di:
– orari di lavoro
– tempo massimo di attesa prima che la vostra richiesta venga presa in carico da qualcuno
– tempo massimo di attesa per una prima risposta (tempo di risposta)
– meno spesso, il tempo massimo che dovete attendere prima che la vostra richiesta venga elaborata e soddisfatta (tempo di risoluzione). Questo è potenzialmente rischioso, perché alcuni problemi tecnici richiedono un’indagine e il tempo investito può diventare imprevedibile.
Il tema delle metriche è uno di quelli che spingono i team a spostarsi verso tool informatici dedicati, e non c’è da sorprendersi se JIRA Service Desk fornisce nativamente una serie di funzionalità di misurazione, che possono essere ulteriormente potenziate con add-on di reportistica. Nella versione out-of-the-box, l’elemento centrale è la SLA, che può essere definita in base a regole e timer automatici.
Va detto che il cambiamento più difficile è quello culturale: si deve capire che “il centro del mondo” è il cliente, e non il sistema IT che deve essere riparato. Per questo, sfortunatamente, non c’è metodo o strumento che tenga; tuttavia, adottare un approccio quantitativo e metriche ben progettate ci aiuta a capire se ci stiamo avvicinando o allontanando dall’obiettivo.
Esiste anche una metrica “oggettivo/soggettiva”, che è il gradimento dell’utente: anche se dipende da vari fattori, non sempre sotto il controllo di chi gestisce il servizio e in parte indipendenti dalla qualità del servizio stesso, è sicuramente la più facile da tenere sotto controllo sul lungo periodo.
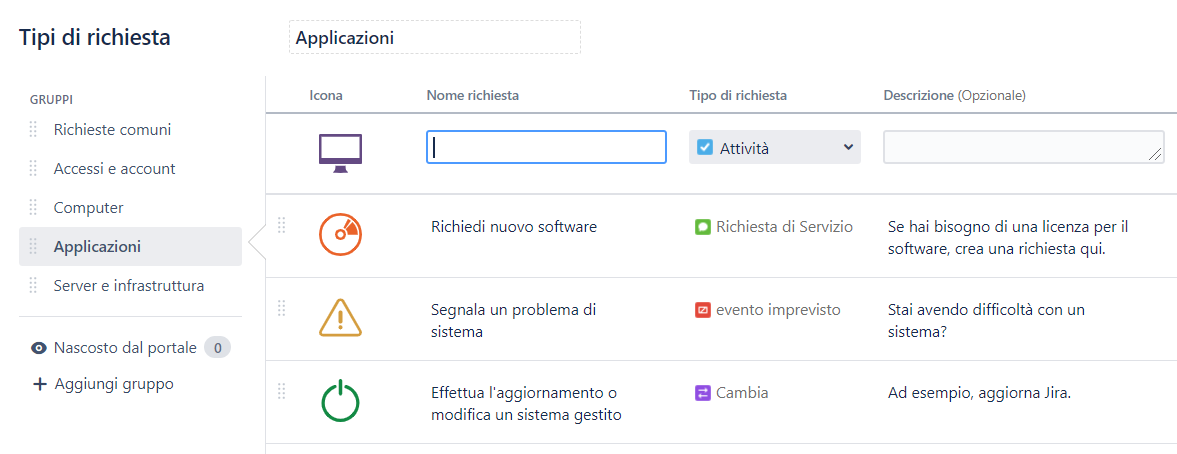
Passo 4: tipi di richieste
Come tante Marie Kondo, stiamo proseguendo nel nostro percorso di riordino: a questo punto vogliamo creare dei cassetti nei quali riporre le cose di un certo tipo. Naturalmente non si parla di maglioni invernali e biancheria, ma di distinguere ciò che è un’attività di riparazione da un intervento migliorativo o un’evoluzione del nostro sistema IT. La finalità comunque è la stessa: oggetti diversi vanno trattati in maniera diversa, e se nel cassetto dei maglioni metterò l’antitarme, per gli interventi di evoluzione dovrò prevedere specifiche policy di rollback, nel caso in cui la modifica non vada a buon fine; per i guasti dovrò definire una frequenza con cui tenere informato l’utente, e così via.
Le richieste più comuni sono definite da standard come l’ITIL, e sono denominate:
- Incident
- Service Request
- Problem
- Change
Un Incident è definito come “un’interruzione o una riduzione non pianificata della qualità di un servizio IT”. In breve, qualcosa si è rotto o funziona male.
Un Incident viene risolto correttamente quando viene ristabilita la qualità prevista del servizio IT: la logica è ben diversa da “l’abbiamo patchato” o “consegneremo un bugfix entro la prossima release”. Inoltre, gli Incident possono essere escalati, il che significa che il loro impatto è così grave da richiedere risorse extra o il coinvolgimento di altre persone. Infine, durante gli Incident si raccomanda di mantenere una corretta comunicazione con gli utenti del servizio, aggiornandoli regolarmente.
Uno dei principi più pratici che si possono applicare agli Incident è quello di avere una strategia di prioritizzazione. Finora abbiamo dato quasi per scontato che i ticket venissero elaborati in ordine cronologico (First Come, First Served) o secondo un criterio soggettivo di urgenza. Il fatto è che per l’utente medio tutti i biglietti sono urgenti. Se non le si permette di stabilire una priorità, è probabile che scriva “URGENTE” nel titolo del biglietto.
D’altra parte, è importante per il rendimento complessivo e la sostenibilità del vostro Service Management che ogni Incident sia trattato secondo un criterio di priorità reale e oggettivo. Questo permette di tenere sotto controllo la velocità complessiva di elaborazione e di rispettare i Service Level Agreement.
Più facile a dirsi che a farsi, perché in molti casi non è facile capire quanto velocemente un Incident debba essere affrontato fino a quando non lo si è esaminato – a quel punto ci si sta già lavorando, e la priorità non ha più importanza.
In realtà, la priorità può essere definita sulla base di due parametri che sono facili da categorizzare prima di effettuare qualsiasi indagine:
– Impatto, il grado in cui l’azienda risente della cosa
– Urgenza, la velocità con cui la questione deve essere affrontata e risolta.
A seconda dell’insieme dei valori di ciascuno di questi due campi di parametri, è possibile progettare una tabella in cui la priorità è una funzione dell’impatto e dell’urgenza; questa tabella è spesso chiamata matrice impatto-urgenza.
Una volta che si nota che lo stesso tipo di Incident si verifica dieci volte in un certo lasso di tempo, il fastidio ci potrebbe motivare a indagare la causa originaria. Ad esempio, se molti utenti aprono un Incident perché esauriscono lo spazio disco sul server, dopo aver liberato spazio per dieci volte si potrebbe sospettare di dover acquistare un nuovo disco rigido.
Un Problem è semplicemente “la causa alla base di uno o più Incident” e lo si vuole rimuovere, in modo da eliminare anche gli Incident futuri.
(Suggerimento: a volte si può solo “mitigare” il Problem, perché non è possibile acquistare un nuovo disco rigido. Introdurre la log rotation potrebbe “mitigare” l’impatto di questo Problem).
Una Service Request si potrebbe definire come “tutto ciò che serve e che non è rotto”; più formalmente, la richiesta di qualcosa da fornire, che si tratti di un nuovo hardware, di un’informazione, di un reset della password, dell’installazione di un software.
Infine, una Change è un modello distinto per descrivere cose come:
- aggiornamenti software e hardware
- bugfix e hotfix
- configurazioni
- plug-in
Se un utente chiede “Posso avere accesso alla directory aziendale” e questo richiede un modulo aggiuntivo, probabilmente nasce come Service Request, poi valutata e convertita in una Change.
Tutte queste entità sono modellate nativamente da JIRA Service Desk, e su di esse è stata ottenuta anche una certificazione ITIL PinkVERIFY™.
Abbiamo finito?
Una volta che avete messo in ordine casa e sistemato tutto nei cassetti, non toccate più niente? Non credo proprio…
Lo stesso vale per la gestione del vostro servizio IT: una volta che avrete fatto ordine, dovrete mantenere questa disciplina come abitudine. Esattamente come il metodo Marie Kondo, l’IT Service Management non è una ricetta magica che da sola risolve tutti i problemi: è un metodo strutturato che può essere applicato per conseguire un risultato, ma per funzionare deve diventare parte del nostro lavoro e della nostra organizzazione. In altre parole: se ci crediamo e lo applichiamo funziona, altrimenti torniamo rapidamente al punto di partenza.
Però coraggio, una gran parte del lavoro è fatta!